Nhắc đến NVIDIA, nhiều người sẽ nghĩ ngay đến các sản phẩm đồ hoạ phổ thông dành cho game (GeForce) hoặc chuyên nghiệp hỗ trợ dựng hình (Quadro). Thời gian gần đây, NVIDIA còn được phần đông người tiêu dùng biết đến như một hãng thiết kế chip SoC ARM dùng cho smartphone & tablet (Tegra). Nhưng ít người để ý rằng hãng này còn là một cái tên lớn trong làng siêu điện toán (HPC) với dòng sản phẩm Tesla. Tại
hội thảo công nghệ GPU (GTC 2012) của hãng này tuần trước, NVIDIA vừa tiết lộ về 2 model Tesla mới nhất của hãng này: K10 dựa trên chip GK104 và K20 dựa trên chip GK110.
GK110 - Khủng long từ trong trứng
Một "truyền thống" thường gặp ở NVIDIA là hãng này "rất thích" làm ra những con chip cực to. "Càng to càng mập càng chứng tỏ đẳng cấp", đấy là phong cách của NVIDIA. Điểm nhấn chính của GTC 2012 là chiếc card Tesla K20, vốn dựa trên sức mạnh của con chip GK110. Con chip này không nằm ngoài "truyền thống" trên. Với 7,1 tỷ trans được sản xuất trên tiến trình 28nm (TSMC gia công), con chip này gần như chiếm ngôi đầu bảng về độ "khủng long" của nó.
Die chip GK110 với 15 khối SMX.
Nói "gần như" là vì hiện GK110 chưa thực sự xuất hiện. Đúng hơn là nó chỉ mới hiện diện trên giấy tờ. Ngoại trừ Tesla K10 dựa trên chip GK104 vốn đã có mặt trên thị trường, K20 dự kiến sẽ xuất hiện vào Q4 năm nay. Có nghĩa GK110 cũng phải đến thời điểm ấy mới bước ra sân khấu. Mà chúng ta không biết liệu tới Q4 này thì có hãng nào khác muốn "giành" ngôi vị chip to nhất hành tinh hay không. Còn tính tới hiện tại, con chip lớn nhất là Tahiti dùng trên card Radeon HD 7900 do AMD sản xuất, vốn có tới 4,3 tỷ trans. Đứng thứ hai là GK104 dùng trên các model GeForce GTX 670 & 680 của NVIDIA với 3,54 tỷ trans. Thứ ba là GF100 có trên GTX 480 cũng của NVIDIA với 3,2 tỷ trans. Ngay đến con chip lớn nhất hiện nay của Intel là Westmere-EX gồm 10 nhân cũng "chỉ mới" đạt 2,6 tỷ trans.
Tuy rằng GK110 vẫn chỉ mới là con chip "trên giấy", song NVIDIA khá "tử tế" khi cung cấp cho cộng đồng công nghệ khá nhiều tài liệu về nó. Và chúng ta có một hình (render) cấu tạo GK110 để tiện hình dung về nó.
Sơ nét về cấu tạo
Chữ GK trong tên con chip là viết tắt của GeForce Kepler, tức con chip GK110 cũng dựa trên
kiến trúc Kepler như GK104. Song GK104 trên thực tế không dành cho HPC, vì năng lực tính toán chính xác kép (
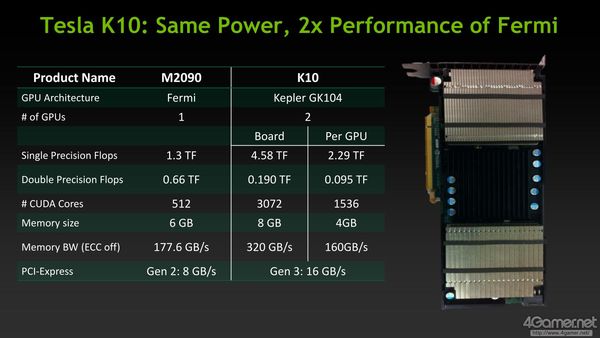
double precision - DP) cực thấp của nó (tính toán khoa học cần độ chính xác cao). Ngay cả con chip GF110 (GeForce Fermi) "cũ" vẫn có năng lực DP cao hơn GK104: 0,66 vs. 0,095 TFlops. GK104 chỉ tốt hơn ở năng lực chính xác đơn (
single precision): 1,3 vs. 2,3 TFlops. Mặc dù vậy bạn cần lưu ý rằng GF110 chỉ có 512 nhân xử lý (SP) trong khi GK104 có đến 1536 SP (gấp 3 lần).
Năng lực DP của K10 thậm chí kém cả đàn anh Fermi.
Vì vậy mà Tesla K10 (gồm 2 chip GK104) thực ra không phải quân bài chính của NVIDIA cho mảng HPC, mà là K20 (chỉ có 1 chip GK110).
Vậy GK110 có khác biệt gì so với GK104 để có thể tiến chân vào mảng HPC? Đấy chính là năng lực DP, và khác biệt này nằm ở khối đơn vị cơ bản nhất của kiến trúc Kepler - SMX. SMX về căn bản là sự tiến hoá của khối SM trên kiến trúc Fermi. Nếu 1 SM lúc trước chỉ có 32 SP thì 1 SMX có đến 192 SP (gấp 6 lần). Tuy vậy xung nhịp của các SP Kepler bị giảm đi còn 1/2 so với Fermi, nên thực tế hiệu năng chỉ tăng lên 3 lần. Nhờ vào tiến trình 28nm giúp thu nhỏ transistor xuống còn 1/2 so với tiến trình 40nm và từ đấy tiêu thụ ít điện hơn, hiệu năng trên Kepler tăng gấp 3 lần Fermi (tính trên cùng mức năng lượng bỏ ra).
Sơ đồ khối toàn chip GK110.
Và điểm cốt yếu nhất ở SMX của GK110: nó có các đơn vị tính toán DP (DPU). GK104 không có DPU nên nếu muốn thực hiện DP, GK104 phải "tổng động viên" toàn bộ khối SMX tham gia. Lượng SMX trên GK104 là 8 khối, quá ít so với 64 DPU mà 1 khối SMX GK110 có. Lại nói về GK110, tổng SMX trên con chip này là 15 khối, tức toàn mảnh silicon 7,1 tỷ trans có 960 DPU. 960 DPU này mang lại năng lực DP lớn đến bao nhiêu? NVIDIA chưa công bố mà chỉ nói nó sẽ gấp 3 lần GF110. Vậy chúng ta có thể "đoán mò" rằng GK110 đạt 0,66 x 3 = 1,98 TFlops. Tất nhiên con số sau cùng sẽ tuỳ theo lượng SP thực cũng như xung thực của con chip.
Có hay không phiên bản GeForce dành cho game?
Chi tiết thú vị là dù đã công bố sơ đồ khối của toàn con chip song NVIDIA chưa khẳng định gì về số nhân cụ thể, cũng như hiệu năng thực của nó. Tại sao?
Vấn đề ở kích thước con chip. Ngay cả được sản xuất trên tiến trình 28nm, 7,1 tỷ trans vẫn là con số cực lớn. Cứ giả định rằng mật độ trans trên GK110 bằng với GK104 (3,54 tỷ @ 294 mm2), thì chúng ta có thể ước đoán GK110 sẽ bự tới 590 mm2!!! Để bạn tiện hình dung, chip GF100 (GTX 480) có kích thước 529 mm2, chip GT200 (GTX 280) có kích thước 576 mm2, chip G80 (GeForce 8800 Ultra) có kích thước 484 mm2. Như vậy về mặt lý thuyết, GK110 sẽ là con chip lớn nhất (xét cả về lượng trans lẫn kích thước die) mà NVIDIA từng làm ra!
Chiếc card Tesla không có cổng tín hiệu nào để xuất ra màn hình ngoài.
Có một quy luật đánh đổi trong thiết kế chip: chip càng to thì tỷ lệ lỗi & chi phí sản xuất càng lớn, hiệu suất sản xuất (số lượng chip hoàn chỉnh) càng thấp. Và điều này đã từng xảy ra với chip GF100 (40nm) vài năm trước và GK104 (28nm) vừa mới đây, do các dây chuyền của TSMC gặp sự cố trong sản xuất. Hầu hết các khách hàng 28nm của TSMC đều ca thán vì sản lượng thấp. Vậy với con chip "khủng long" GK110, liệu có bao nhiêu hy vọng về một sản lượng "chấp nhận được"?
Bài toán kinh tế đơn giản: sản lượng thấp dẫn tới chi phí sản xuất cao. Mà chi phí sản xuất càng cao thì càng khó hạ giá thành sản phẩm. GeForce là dòng sản phẩm cho người dùng phổ thông, nên về mặt "nguyên tắc" thị trường, giá của chúng không thể quá cao. Cứ cho rằng NVIDIA tốn gấp đôi chi phí để làm ra 1 chip GK110 (so với GK104) thì giá thành sau cùng của chiếc GeForce dựa trên GK110 (nếu có) cũng sẽ xấp xỉ với GTX 690 (phiên bản 2 chip GK104), tức 1.000 USD! Mà ngay cả như thế, chiếc card GeForce GK110 cũng không mạnh tương đương (về mặt game) GTX 690. Vì nó chỉ có 2.880 SP (192 SP x 15 SMX), chỉ bằng 93,75% lượng SP của GTX 690. Do vậy xét "sơ sơ" về mặt hiệu năng & chi phí sản xuất, GK110 hoàn toàn không phù hợp cho mục tiêu chơi game.
GTX 690 - Chiếc card chơi game 2 chip đắt nhất hiện nay.
Sinh ra cho siêu điện toán
Thực sự tại GTC 2012, NVIDIA không đề cập tới bất kỳ model GeForce hay Quadro nào dựa trên GK110, chỉ có duy nhất model Tesla K20. Điều này trừ yếu tố hiệu năng gaming kém đã bàn ở trên, còn xuất phát từ bối cảnh sử dụng những chiếc card. Các game cùng các ứng dụng dựng hình phổ thông thực ra chỉ cần tới năng lực chính xác đơn, vốn được tạo ra bởi các SP. Các ứng dụng trên hầu như không động chạm gì tới các DPU. DPU chỉ phát huy vai trò của mình ở các ứng dụng HPC (dự báo tài chính, mô phỏng phản ứng sinh hoá lý, phân tích số liệu thống kê, xử lý ảnh viễn thám, dự báo thời tiết, động đất, sóng thần...)
Tuy vậy tôi lặp lại phần này không phải vì 960 DPU (con số hoàn chỉnh) có trên GK110. Mà vì các tính năng khác được NVIDIA tối ưu cho HPC. 2 tính năng nổi bật nhất sẽ giúp khai thác K20 hiệu quả hơn các model Tesla khác gồm Dynamic Parallelism và Hyper-Q.
Dynamic Parallelism
Tạo ra nhiều "cơ bắp" (nhân xử lý) chỉ mới là một mặt của vấn đề. Vì không phải lúc nào toàn bộ số "cơ bắp" ấy cũng được dùng triệt để. Ví dụ ở đây là một kernel chương trình do CPU gửi cho GPU xử lý, nhưng GPU chỉ dùng một phần số "cơ bắp" là đã xử lý xong kernel này, phần còn lại hoàn toàn không dùng tới. Rồi GPU gửi trả dữ liệu cho CPU. CPU nhận được dữ liệu mới lại tiếp tục gửi kernel mới cho GPU làm việc. Và cứ thế, có lúc toàn GPU làm việc hết công suất, có lúc không. Nói đơn giản: sức mạnh GPU bị lãng phí về mặt thời gian.
Dynamic Parallelism là cơ chế cho phép GPU "tự túc" tạo ra các kernel để làm việc tiếp, mà không cần phải "hỏi han" CPU. GPU lúc này chỉ cần trả về dữ liệu sau cùng mà CPU cần. Hiểu nôm na: giống như huyện và tỉnh, tỉnh giao cho huyện trong năm nay phải hoàn thành bao nhiêu công trình, huyện sẽ tự đặt ra các dự án (sao cho vẫn phù hợp với quy hoạch của tỉnh) và tự tiến hành; chứ không như lúc trước, tỉnh giao cái gì, huyện làm cái nấy, không cần biết có hiệu quả hay không.
Hyper-Q
Đây là một tính năng khác cũng nhằm mục đích hạn chế sự lãng phí thời gian, nhưng ở quy mô cao hơn. Lại mượn ví dụ tỉnh / huyện: thay vì mỗi năm chỉ giao cho huyện 1 dự án, nay huyện lập ra nhiều ban bệ (ảo) để tiếp nhận được nhiều dự án hơn mà tỉnh giao, song vẫn nằm ở mức huyện "đủ sức cáng đáng". Quay lại GK110, đôi khi số lượng các kernel phát sinh (1 MPI) vẫn chưa tiêu thụ hết tài nguyên tính toán của con chip, vẫn còn phần thừa không hoạt động. NVIDIA khắc phục tình trạng này bằng cách tăng lượng MPI (Message Passing Interface) lên con số 32 (có lẽ "đủ" để "vắt kiệt" con chip). Tức CPU cứ việc gửi thật nhiều việc cho GPU, còn khi nào GPU hoàn tất cái đấy tính sau!
Sơ kết
Điện toán phức hợp (heterogeneous computing) đang bắt đầu trở thành trào lưu mới của giới công nghệ. Về mặt phần cứng là kiến trúc chip và phần mềm là OpenCL, CUDA, DirectCompute... Một phần quan trọng của nhóm điện toán này là điện toán GPU (GPGPU) với 2 đại diện tiêu biểu là AMD và NVIDIA. Về AMD, hãng này có kiến trúc x86 trong tay và họ tạo ra APU. Còn NVIDIA, "xui xẻo" không được Intel cấp giấy phép x86 nên đơn vị này đành phải phát huy tối đa khả năng của GPU, mà dòng sản phẩm Tesla là đỉnh cao nhất.
Với kiến trúc Fermi, NVIDIA đã thiết lập một vị thế khá vững trên trường HPC. Và nay, họ đang cố gắng củng cố thêm chỗ đứng ấy với kiến trúc Kepler (nhưng chúng ta nên gọi là Big Kepler hay Kepler DP nhỉ?). Trước mắt về lý thuyết, GK110 sẽ là con chip cực mạnh cho HPC, không chỉ về mặt năng lực DP mà còn về sự tối ưu công nghệ cho nó. Đây là điểm mà AMD vẫn kém so với NVIDIA. Song không có sản phẩm nào là vô địch mãi mãi, cũng không có gì là tuyệt đối trong giới công nghệ. Chúng ta hãy xem thử liệu đến Q4 tới, NVIDIA sẽ thực sự mang gì đến với thế giới, thay cho những con số trên giấy của hôm nay.
Tổng hợp.


![[Video] NVIDIA demo năng lực tính toán siêu khủng của kiến trúc đồ hoạ Kepler](https://gamek.mediacdn.vn/zoom/170_113/Bn4MfiQraO4LRHcMZk7W6tWIgLkccc/Image/2012/05/NVIDIA-GTC-2012-ava_ab43b.jpg)